從 Apache Spark 到 Databricks:一個開源專案如何成為成功的商業模式

Databricks 是一家創立於 2013 年的美國軟體公司,總部位於加利福尼亞州舊金山。該公司的使命是協助資料科學家、資料工程師和企業客戶更輕鬆地進行大規模數據處理和分析。在資料科學界,大部分企業用戶都有聽過或使用過 Databricks 的產品,像是 Spark 和 MLflow。
事實上 Databricks 的創辦人團隊正是開發出分散式資料處理框架 Aphache Spark 的原班人馬。在 Spark 開源之後,快速地在企業界中廣受歡迎,不過正當 AWS 靠著托管的 Spark 服務,每年收取幾億美元的營收之際,Databricks 還在靠辦研討會賣 T-shirt 維生。明明是自己開發出來的技術,卻是別人賺得滿缽滿盆,Databricks 並沒有被這樣的相對剝奪感打倒,他們在競爭激烈的大數據雲服務中堅信自己的商業嗅覺,做出關鍵的發展路線決策,2021 年估值來到 380 億美金,在短短幾年內成長為獨角獸公司。讓我們來看看他們的故事。
歡迎訂閱《透光帶》電子報:https://lichengen.substack.com/
2000 以降的大數據發展
Databricks 最著名的產品之一是 Apache Spark,Spark 是一個流行的開源資處理框架,它支援分散式資料處理、機器學習、圖形處理和串流處理等多種資料處理工作負載。Databricks 還提供了一些其他產品,如 Delta Lake、MLflow 和 Koalas 等,這些產品都是針對資料工程、機器學習和資料科學應用的。
要理解這些產品發展的脈絡,勢必要回顧科技發展對資料需求的演變。
1970–2000 年,結構化資料
2000 年以前,幾乎都是人為收集的資料,資料量小,用傳統的關聯式資料庫存放資料就很夠用了。應用多為傳統的資料探勘、統計分析,建置資料儀表板。
資料分析、和大數據起源於資料庫管理這一悠久的領域。它在很大程度上依賴於儲存在關聯式資料庫管理系統(RDBMS)中的數據所共有的儲存、提取和優化技術。這些系統中使用的技術,如結構化查詢語言(SQL)和數據的提取、轉換和加載(ETL),在1970年代開始專業化。資料庫管理和資料倉庫系統仍然是現代大數據解決方案的基本組成部分。能夠快速儲存和檢索資料庫中的資料或在大型資料集中查找特定資訊,仍然是大數據分析的核心要求。在這一階段開發的關聯式資料庫管理技術和其它資料處理技術,依舊深深地嵌入在領先的 IT 廠商(如微軟、谷歌和亞馬遜)的大數據解決方案中。
2000–2010 年,網頁型的非結構化資料
從 21 世紀初開始,社群平台興起,開始有輿情、網絡、影像的分析需求。此時資料的型態開始變得多元且複雜,大量的使用者,也讓社群平台收集到的資料量級大幅提升。
網路和各式應用 (App) 開始產生巨大的資料量。除了這些 App 存在關聯式資料庫中的資料外,針對 IP 的互動也開始網絡般的非結構化資料,從而推生出對社群用戶的需求和行為的洞察作為新的商業模式。隨著網絡流量和電子商務的越來越普及,Yahoo、Amazon 和 eBay 等公司開始通過分析點擊率、特定 IP 的位置資訊和搜尋、瀏覽紀錄來分析客戶行為,強化自身的服務。
2010 年 ~ 2020 年,行動裝置與物聯網資料
行動裝置與各式智慧家居開始普及。2011年,行動裝置和平板電腦的數量首次超過了筆記型電腦和個人電腦的數量。2020年,估計有100億台設備連接到網路,而所有這些設備每時每刻都在產生資料。
行動設備不僅提供了分析行為資料(如點擊和搜索查詢)的可能性,而且它們還提供了儲存和分析 GPS 位置資料的機會。通過這些設備,我們有可能追蹤運動,分析身體行為,甚至與健康有關的數據(例如,你每天走的步數)。
同時,基於傳感器的互聯網設備的興起,使資料的產生量更大。著名的「物聯網」(IoT),每天都有數以百萬計的新電視、可穿戴設備甚至冰箱連接到互聯網,提供大量的額外資料集。由於這種發展預計不會很快停止,可以說從這些新資料源中提取有意義和有價值的資訊的競賽才剛剛開始。
大概從 2000 年以降,企業收集到的資料已經大幅超過人腦可以處理的負荷量,要對這些資料進行分析,進而獲得商業洞察,需要新技術的支援。大量、多樣的資料,讓業界面臨到兩個主要問題:如何儲存資料?如何處理資料?
分散式資料處理框架 Spark
2005年之前,資料庫系統是運行在單一主機上。當然,每年主機的效能變得越來越大、越來越快,使資料庫系統能儲存更多的資料。但基本上,基本架構保持不變。
2006 年,Doug Cutting 和他在 Yahoo 的團隊推出了 Hadoop,這是一個重大的突破。Hadoop 讓資料庫系統的橫向擴展程度前所未有地提高。開發者可以連接 10、50 或 100 台主機,每台主機都運行 Linux 和 Hadoop。數據也可以分布在所有機器的所有硬碟上,計算作業可以在所有機器的所有核心上運行。
Hadoop 是資料庫系統的一個巨大突破,因為硬碟相對便宜。幾年之內,許多公司就自行架設數百個節點的 Hadoop 集群,然後讓數千台主機一起工作。
天下沒有免費的午餐,Hadoop 也有它的缺點。它所使用的程式框架(Hadoop MapReduce)的學習曲線很陡,而且MapReduce 在生成最終結果之前會產生許多中間結果,所有中間結果都寫入硬碟裡,導致處理的速度非常緩慢。
2009 年,Matei Zaharia 在加州大學柏克萊分校 AMPLab 開發出叢集運算框架 Spark。相對於Hadoop 的 MapReduce 會在執行完工作後將中介資料存放到磁碟中,Spark 使用了記憶體內運算技術,能在資料尚未寫入硬碟時即在記憶體內分析運算。Spark 在記憶體內執行程式的運算速度能做到比 Hadoop MapReduce 的運算速度快上 100 倍,即便是執行程式於硬碟時,Spark 也能快上 10 倍速度。
更棒的是 Spark 允許使用者將資料載入至叢集記憶體,並多次對其進行查詢,非常適合用於機器學習演算法。2013年,該專案被捐贈給 Apache 軟體基金會並切換授權條款至 Apache2.0,成為後人廣為人知的 Apache Spark。
Spark 提供了業界急迫所需的大量資料的資料處理問題,2013年,知名創投 Andreessen Horowitz 的聯合創始人 Ben Horowitz 向 Spark 團隊他們投資了1400萬美元,並鼓勵他們創建一家公司,作為運行 Apache Spark 的平台。因此,Databricks 於2013年成立。
資料儲存的典範轉移 Lakehouse
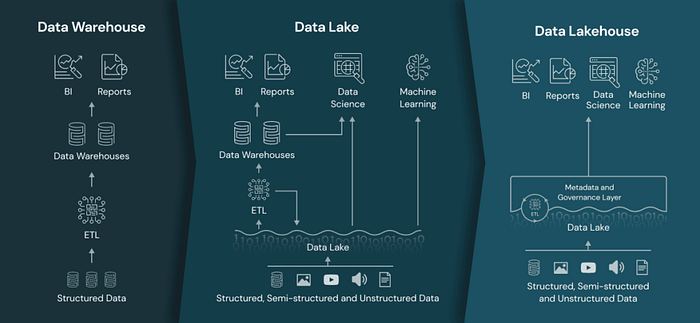
1980年代末開始,資料倉儲(data warehouse)技術不斷發展,儘管資料倉儲非常適合結構化數據,但許多現代企業必須處理非結構化資料、半結構化資料和具有高度多樣性、速度和容量的資料。資料倉儲並不適用於這些使用情境。
隨著公司開始從許多不同的來源收集大量數據,資料架構師開始設想一個單一的系統來儲存許多不同的分析產品和工作負載的數據。2010年,企業開始使用資料湖(data lake),用來儲存各種格式的原始資料的倉庫。不過資料湖缺少一些關鍵功能:不支援 database transaction,不強制檢查資料品質,缺乏一致性與隔離性,讓它幾乎無法讓新增、讀取、批次處理與串流處理同時混雜著發生。
2000 以後,大量的資料更為資料儲存帶來三大挑戰:
- 資料類型逐漸多元化,除了純文字,影像、聲音類型的檔案也逐漸變多。不同資料之間的差異性,讓他們難以被儲存在傳統的資料倉儲裡。
- 企業既有的地端服務的確結合了資料儲存與運算,但是其架構難以擴增或是調降。
- 企業對機器學習或是 AI 的專案需求越來越多,資料儲存需要為這些情境做優化。
為了滿足這些需求,許多企業選擇同時建置資料倉儲與資料湖以及其他特殊使用情境的系統(例如時序類型的資料庫)。然而擁有多套系統不僅大幅增加維運成本,資料的使用者也無可避免地需要在不同系統之間移動或複製資料。
2017 年 Databricks 提出一種新的、開放的架構 Lakehouse,結合資料湖和資料倉儲的長處,解決上述的問題與挑戰。其特色如下:
- 支援 database transaction: 在企業營運的日常中,許多資料管道通常會同時讀取和寫入數據。此設計確保了資料的完整性和一致性。
- 資料型別檢查與監控:Lakehouse 能夠推理數據完整性,並且應該有強大的管理和審查機制。
- 支援 BI:直接在資料源上使用 BI 工具,可以大幅減少資料在資料湖與資料倉儲之間操作兩份資料副本的成本。
- 儲存與運算分離: 儲存與運算各自使用單獨的叢集(cluster),因此能夠支援更多使用者使用,以及更大的資料量級。
- 開放性:Lakehouse 使用的儲存格式是開放並且標準化的,並提供 API 以便各種工具和引擎(包括機器學習和 Python / R libraries)可以直接高效地調用資料。
- 支援多樣化數據類型: Lakehouse 可用於儲存、精煉、分析許多新數據應用所需的數據類型,包括影像、影片、音檔、半結構化數據和文本。
- End-to-end 串流處理: 即時取得當下最新數據,在許多企業中是基本標準,串流處理功能滿足此類即時報告的需求。
看準市場缺口的三大關鍵決策
在公司成立的早期,團隊做出的三個決定影響深遠。
- 堅持提供雲服務
團隊堅信是雲端運算未來的方向。Databricks 聯合創始人 Ion Stoica 和 Matei Zaharia 是〈A Berkeley View of Cloud Computing〉的作者,這篇 2009 年的論文提出未來無論是應用軟體 (Applications software)、基礎建設軟體(Infrastructure software) 還是硬體系統(Hardware system)都要能夠滿足水平擴展的需求。這篇論文在雲端運算發展中影響深遠,被引用上萬次。在公司早期的階段,不是所有人都深刻理解堅持雲服務的理念,每年仍然會被新加入的員工挑戰,融資時也會被投資人挑戰,同時也不被客戶接受。所幸內部堅持雲服務,投資人有耐心,客戶在 2018 年後也開始大規模上雲。 - 不做技術支援服務(Technical support)
技術支援服務依賴人員擴張以支援更多客戶,不具備大規模擴張的能力,而且利潤率也較低,商業模式不如雲服務。2015年時,Spark 在客戶中已經很有名氣,很多客戶找到團隊希望能提供咨詢和支援服務,甚至有客戶願意出 1000 萬美元。但考量到會分散團隊的注意力,不利於長期發展,經營團隊還是放棄了這塊業務。2018 年,很多客戶已經看到雲服務的未來,表示未來會遷移上雲,但不確定什麽時候會遷移;而到 2019 年,很多客戶已經行動起來,開始遷移上雲,其後雲服務已經成為業界的共識。 - 專注於資料科學領域
起初創辦人團隊參加 Netflix 的資料科學競賽時,發現大規模數據集無法在一台服務器上完成模型訓練,因此開發了 Spark;後續公司以 Spark 為基礎,選擇數據科學作為業務推廣方向,為數據工程師提供工具,而沒有選擇競爭更激烈的資料倉儲賽道。
當時資料科學的重要性剛被 Facebook、Netflix 等公司提出,許多大多數公司還沒有相應的職位,在沒有激烈的競爭下,Spark 很快被企業接受;而資料倉儲賽道則面臨老牌的 Teradata 公司,以及 AWS 的 RedShift 的競爭。
與 AWS 的競爭角力
2015 年左右,AWS 的 EMR 大數據平台托管的 Spark 服務吸引了許多企業客戶使用。Databricks 知道自己要做出差異化,才能從激烈的雲運算市場中爭取到自己的一席之地,主要的策略有三:
- 差異化競爭
延續上述專注於資料科學的脈絡,Databricks 把重心放在挖掘資料科學用戶的核心需求,提供差異化的商業服務,如:可互動式 GUI 介面、多個用戶可以連到同一個叢集以節省資源、權限控管、多人協作、多資料源管理。 - 多雲策略
2017 年 11 月,Databricks 獲得微軟的邀請,合作推出 Azure Databricks。以Apache Spark架構為基礎,整合 Microsoft Azure 上的雲端儲存解決方案,包含 Azure SQL 資料庫及 Cosmos DB,並提供互動式筆記本,讓資料科學團隊能夠使用 R、Python、Scala 和 SQL 等常用語言進行資料協作,藉由彙整各類型的資料,以建立強而有力的機器學習模型,進而提供企業創建巨量資料分析及開發人工智慧應用。
目前 Databricks 已經在多個雲端服務商提供服務,包含 Amazon AWS、Microsoft Azure 以及 Google GCP。 - 銷售策略
在公司發展初期,Databricks 並沒有建立銷售團隊,全靠開發人員社群的口耳相傳。後來意識到資料科學團隊在企業內都屬於少數族群,不可能擴張到很多人時,便開始組建銷售團隊直接與CXO 對接,解決其面臨的痛點,目前已經建立相當規模的銷售團隊專門服務大客戶。
營運表現
從逐年營收來看,2018 年開始有大幅的增長,推測是與微軟的合作獲得相當大的助益。值得注意的是 2021 年後,成長幅度開始趨緩,2022 年甚至出現負成長。營運團隊需要尋找下一階段的成長動能。
從新聞可以觀察到 Databricks 在 2023 年初推出了自己研發的大型語言模型 Dolly 2.0,但效能表現有待加強。推敲背後的考量,可能有以下幾個原因:
- 競爭壓力:目前,許多大型科技公司(如 Google、Microsoft、Amazon 等)都在開發自己的機器學習模型,而這些公司的解決方案通常都與他們的雲端平台緊密結合。這可能會對 Databricks 的競爭力造成影響,因此他們可能需要開發更先進的機器學習模型以保持競爭優勢。
- 客戶需求:Databricks 的客戶群體主要是企業和組織,他們通常需要大規模且高效的數據處理和分析解決方案。這些客戶可能需要更先進的機器學習模型來滿足其業務需求,因此 Databricks 可能會選擇推出自己的 LLM 模型以滿足這些需求。
- 產品擴展:Databricks 的主要產品是 Spark 和 lakehouse,而這些產品通常被用於大規模數據處理和分析。推出自己的 LLM 模型可以進一步擴展其產品線,以提供更完整的機器學習解決方案。
結語
Databricks 也是走 Product-led growth 成長模式的代表公司之一,想要好好寫他們已經一段日子了。我很喜歡他們創辦人都是學術界開源社群背景出身的組成,在市場需求亟需技術突破的時候,讓自己走到浪尖上。他們的創業歷程,很像一群很會唸書、技術卓越的人,突然被丟到浪淘洶湧的商業市場上,努力活下來的故事。
2023 年的 AGI 浪潮襲來,可以肯定的是既有的商業分析需求暫時還不會消失,但看得出來經營團隊還在摸索未來的成長動能。希望他們可以看到漫漫長夜後的曙光。
歡迎訂閱《透光帶》電子報:https://lichengen.substack.com/
